Leveraging Data Recasting to Enhance Tabular Reasoning
About
Creating challenging tabular inference data is essential for learning complex reasoning. Prior work has mostly relied on two data generation strategies. The first is human annotation, which yields linguistically diverse data but is difficult to scale. The second category for creation is synthetic generation, which is scalable and cost effective but lacks inventiveness. In this research, we present a framework for semi-automatically recasting existing tabular data to make use of the benefits of both approaches. We utilize our framework to build tabular NLI instances from five datasets that were initially intended for tasks like table2text creation, tabular Q/A, and semantic parsing. We demonstrate that recasted data could be used as evaluation benchmarks as well as augmentation data to enhance performance on tabular NLI tasks. Furthermore, we investigate the effectiveness of models trained on recasted data in the zero-shot scenario, and analyse trends in performance across different recasted datasets types.
Framework
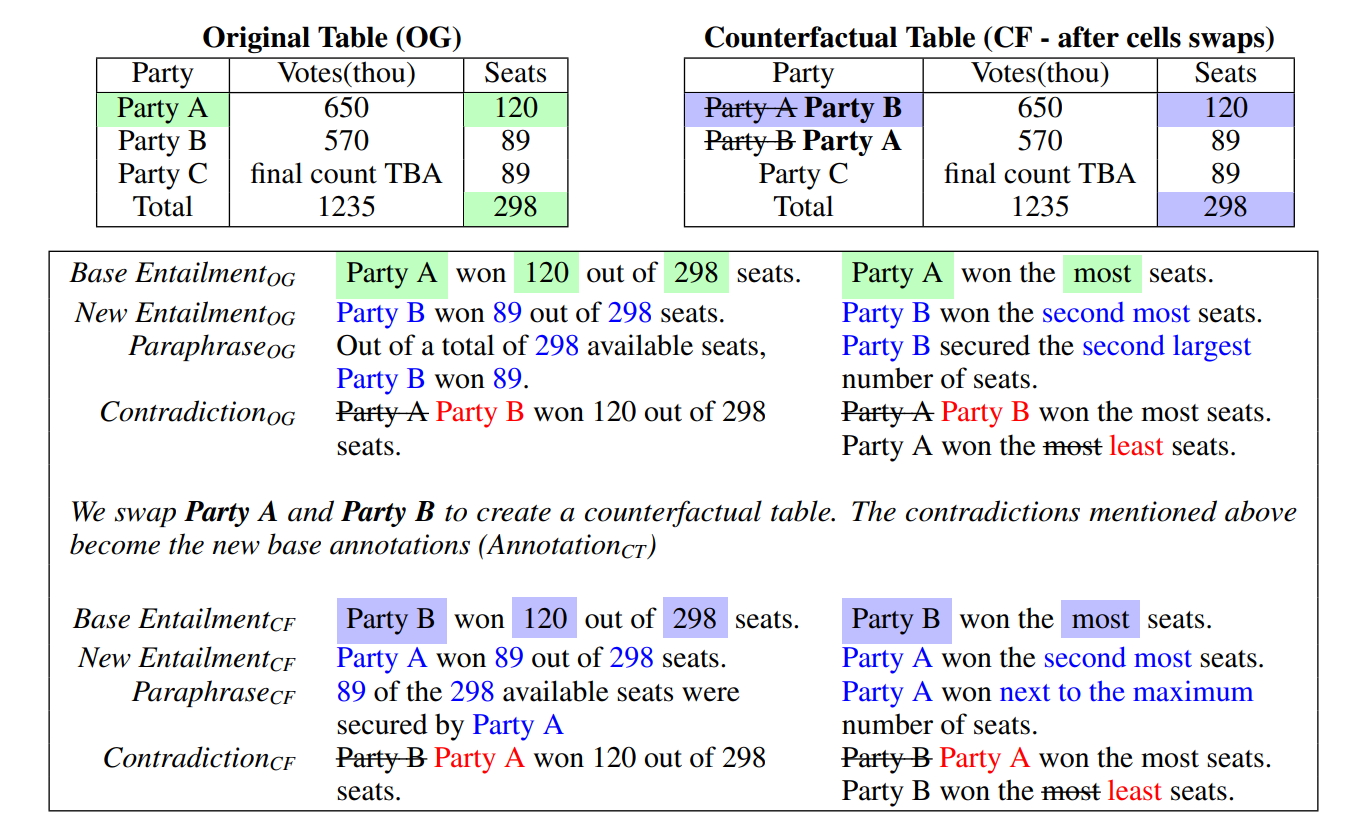
Source Datasets and Recasted Datasets
Using the framework outlined above, we recast the five datasets listed below. All datasets utilise open-domain Wikipedia tables, comparable to TabFact. In addition, these datasets and TabFact share reasoning kinds such as counting, minimum/- maximum, ranking, superlatives, comparatives, and uniqueness, among others. Source datasets and statistics for various recasted datasets are gieven below. QA-TNLI combines recasted data from both FeTaQA and WikiTableQuestions. Test splits are created by randomly sampling 10% samples from each dataset.
| Source Dataset | Generated Dataset | |||
|---|---|---|---|---|
| Dataset | Task | NLI-Dataset | Entail | Contradict | Total | |
| WikiTableQuestions (Pasupat and Liang, 2015a) | Table Question Answering | QA-TNLI | 32k | 77k | 109k | |
| FeTaQA (Nan et al., 2022) | Table Question Answering | |||
| WikiSQL (Zhong et al., 2017) | Table Semantic Parsing | WikiSQL-TNLI | 300k | 385k | 685k | |
| Squall (Shi et al., 2020b) | Table Semantic Parsing | Squall-TNLI | 105k | 93k | 198k | |
| ToTTo (Parikh et al., 2020) | Table To Text Generation | ToTTo-TNLI | 493k | 357k | 850k | |
Experiments and Analysis
We examine the relevance of our recast data across various settings. Overall, we aim to answer the following research questions:- RQ1: How challenging is recast data as a TNLI benchmark?
- RQ2: How effective are models trained on recasted data in a zero shot setting?
- RQ3: How beneficial is recasted data for TNLI data augmentation?
Setup
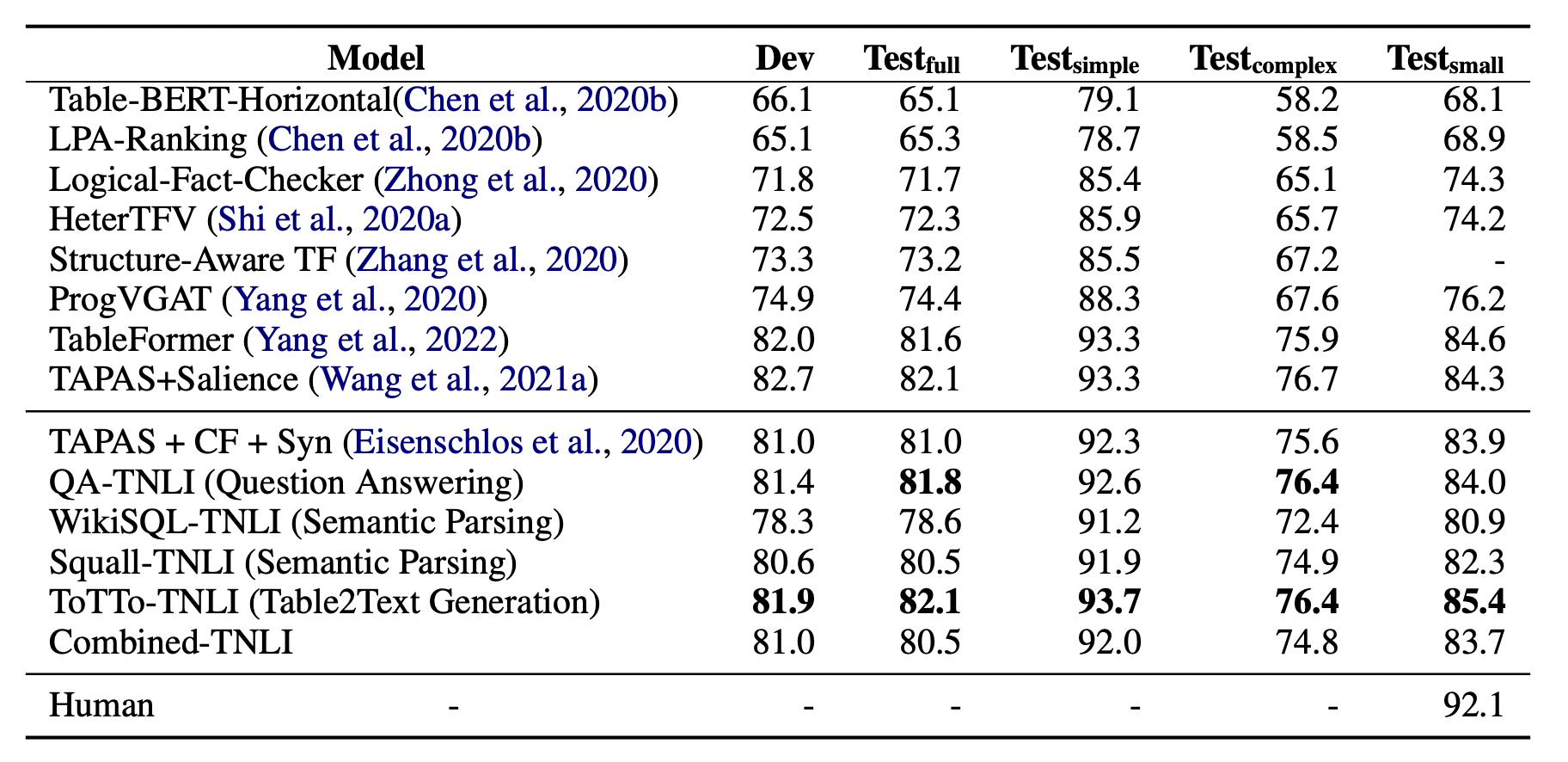
In all experiments, we follow the pre-training pipeline similar to Eisenschlos et al. (2020). We start with TAPAS (Herzig et al., 2020), a tablebased BERT model, and intermediately pre-train it on our recasted data. We then fine-tune the model on the downstream tabular NLI task. Dataset. We use TabFact (Chen et al., 2020b), a benchmark Table NLI dataset, as the end task to report results. TabFact is a binary classification task (with labels: Entail, Refute) on Wikipedia derived tables. We use the standard train and test splits in our experiments, and report the official accuracy metric. TabFact gives simple and complex tags to each example in its test set, referring to statements derived from single and multiple rows respectively. Complex statements encompass a range of aggregation functions applied over multiple rows of table data. We report and analyze our results on simple and complex test data separatelyResults
People
The following people have worked on the paper "Leveraging Data Recasting to Enhance Tabular Reasoning":




Citation
Please cite our paper as below if you use our recasted datasets.
@inproceedings{jena-etal-2022-recasting-tnli,
title = "Leveraging Data Recasting to Enhance Tabular Reasoning",
author = "Jena, Aashna and
Gupta, Vivek and
Shrivastava, Manish and
Eisenschlos, Julian",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
month = dec,
year = "2022",
address = "Online and Abu Dhabi",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2211.12641",
pages = "",
abstract = "Creating challenging tabular inference data is essential for learning complex reasoning. Prior work has mostly relied on two data generation strategies. The first is human annotation, which yields linguistically diverse data but is difficult to scale. The second category for creation is synthetic generation, which is scalable and cost effective but lacks inventiveness. In this research, we present a framework for semi-automatically recasting existing tabular data to make use of the benefits of both approaches. We utilize our framework to build tabular NLI instances from five datasets that were initially intended for tasks like table2text creation, tabular Q/A, and semantic parsing. We demonstrate that recasted data could be used as evaluation benchmarks as well as augmentation data to enhance performance on tabular NLI tasks. Furthermore, we investigate the effectiveness of models trained on recasted data in the zero-shot scenario, and analyse trends in performance across different recasted datasets types.",
}Acknowledgement
We thank members of the Utah NLP group for their valuable insights and suggestions at various stages of the project; and EMNLP 2022 reviewers their helpful comments. Additionally, we appreciate the inputs provided by Vivek Srikumar. Aashna Jena acknowledges support from Google AI and Vivek Gupta acknowledges support from Bloomberg's Data Science Ph.D. Fellowship.